In this article, we will compare block storage vs Object Storage in AWS
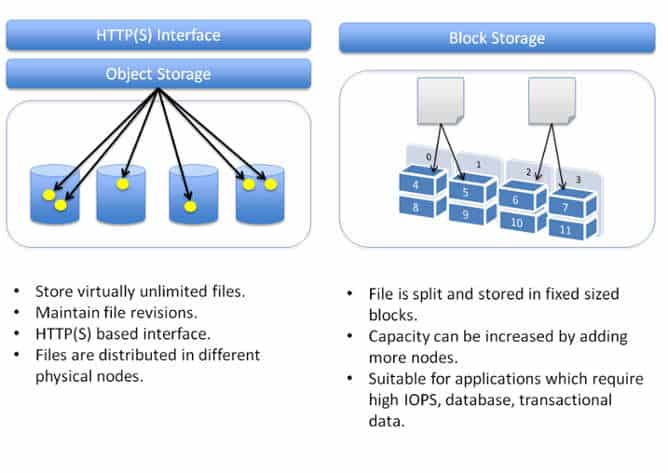
Block Storage: In block storage, the data is stored in terms of blocks.
Let’s assume below diagram consider as a hard disk and whenever you install any filesystem as ext3, ext4 or xfs then the Filesystem divide the storage in small block size, then the storage is saved in terms of blocks.
How to check the block size in Linux OS for the particular disk?
[root@shinde ~]# blockdev --getbsz /dev/sda 4096 [root@shinde ~]#
How to check disk in Linux and where it is mounted
[root@shinde ~]# lsblk | grep sdb sdb 8:16 0 100G 0 disk /mnt [root@shinde ~]#
Check FileSystem created on /dev/sdb block disk
[root@shinde ~]# cat /etc/fstab | grep sdb /dev/sdb /mnt ext4 defaults 0 0 [root@shinde ~]#
What is Block Storage
| 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 |
| 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 |
If you want to save 8kb of data then two blocks will be allocated depends on the data size block is allocated. Data stored in blocks are normally read or written entirely as a whole block at the same time. Most of the file systems are based on block devices.
Every block has an address and application can be called via SCSI call via its’ address and there is no storage side meta-data associated with the block except the address (block has no description, no owner).
Assume there is an Image file which has been stored and you can determine by seeing the block what is stored on particular block
When you save image how it gets stored on a filesystem
| Image | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 |
| 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 | 4096 |
What is Object Storage
Object storage is a data storage architecture that manages data as objects as opposed to blocks of storage. An Object is defined as a data (file) along with all its meta-data which is combined together as an object. This Object is given an ID which is calculated from the content of the object (from the data and metadata). The application can then call object with the unique object ID.
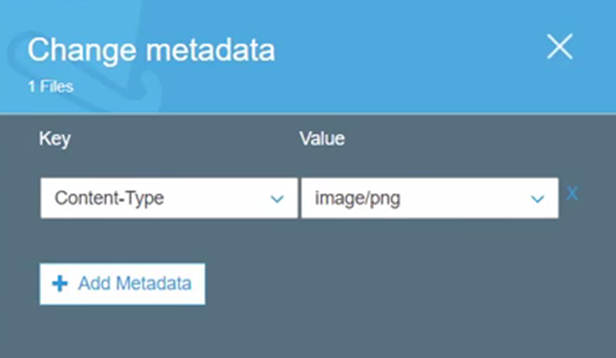
Example: S3 is an Object storage whenever you upload any data to s3bucket, an S3 store with metadata like it tells you the content-type with value and also you can create customer metadata according to your requirement.
Difference between Object Storage and Block Storage
Read this also:





