Would BMW and Ferrari market their cars as “Not a Porsche” instead of “It is a BMW” and “It is a Ferrari”? Probably not. Interestingly, we see this kind of terminology for NoSQL databases, short for Not-Only-SQL-databases. The term covers a diverse set of database management systems that this article has a closer look at.
The Success of SQL Databases
The term NoSQL refers directly to SQL respectively relational databases. Their birth was in the 1970s with IBM’s research prototype System R. The commercial breakthrough came a few years later. It was in the 1980s when commercial products such as Oracle, Informix, and IBM DB2 took off. Two characteristics of SQL databases are relevant for understanding today’s NoSQL phenomenon:
- The relational, aka table-like, data model. Relational databases have a strictly enforced schema. It consists of tables with defined attributes and, potentially, additional constraints. Loading and processing data requires respecting this schema. Otherwise, the database rejects your command with an error message.
- Databases enforce the ACID guarantees: “A” stands for atomicity: a transaction (aka, a group of commands) is either executed completely or all effects are undone. “C” refers to consistency. At the end of a transaction, the database is (again) in a consistent state. The data fulfills all constraints and integrity requirements. “I” stands for isolation. Isolation guarantees that there is no interference with parallel transactions on the same data. “D” stands for durability. Once the database confirms the commit, all changes are stored persistently and cannot get lost.
SQL databases evolved over the years. While they are mature products, vendors such as Oracle, Microsoft, and IBM continue(d) to invest in innovative features such as scalability, ease of handling, automation, or other new and advanced features. Relational databases turned into object-relational in the late 1990s thereby preventing that the new object-oriented databases gained a relevant market share. The reality proved Stonebreaker’s famous statement to be correct: object-oriented databases are a zero-billion-dollar business.
At this time, new areas of data management such as CAD/CAM or spatial-temporal data and geographical information systems (GIS) challenged the traditional relational databases. The new and coming object-oriented databases were better suited for these areas. Still, they failed in the market. The traditional SQL database vendors absorbed the trend by implementing new features such as more flexible table structures, features for handling large documents (Character Large Objects / CLOBs), or binaries (Binary Large Objects / BLOBs). Will the same happen with NoSQL databases – a short hype and forgotten in some years? When I was at the Oracle OpenWorld in London in February 2020 that was their vision (and hope) – everything in their database to which more and more features are added.
Why NoSQL Databases Prosper
NoSQL databases started to catch attention from 2009/2010 onwards as Google trends illustrates (see Figure 1). Their success bases on providing fewer features than traditional databases, (mostly) not on providing new features. They are more lightweight, easy to deploy, and with no or different license fee models. Important trends are Key-Value Stores, and Document and Graph Databases plus highly scalable data processing engines.
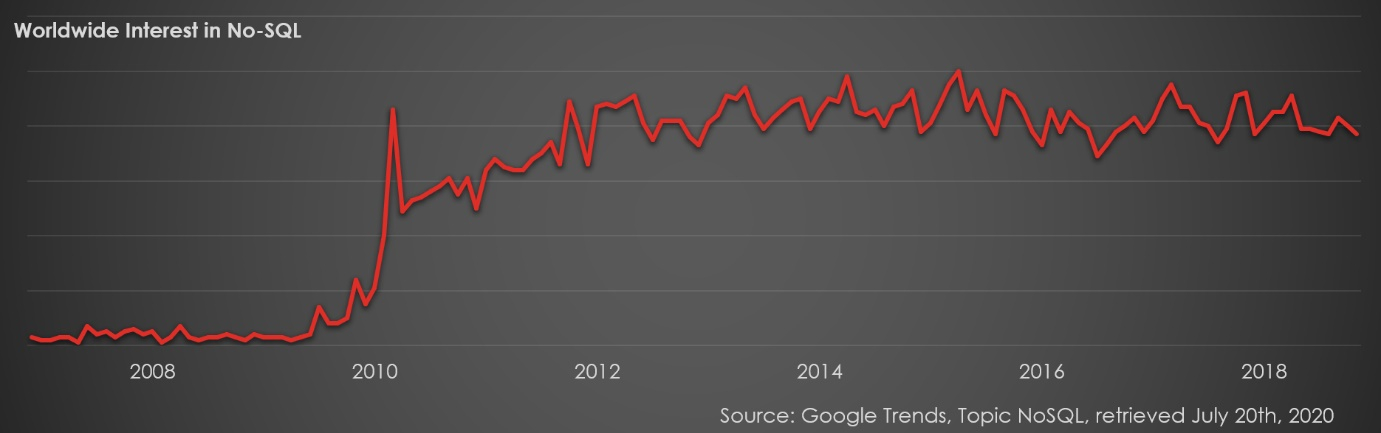
Figure 1: Interest in NoSQL
Key-Value Stores
The data model of key-value stores is extremely limited – pairs of a key and a value. When you know the key (e.g., an IP address), you can retrieve the associated value. For example, the last time a request came from a specific IP address. As always, there are variations when looking at different key-value store products: complex keys, searching for values, in-memory-databases for speed, etc. The main characteristic, however, is the simplistic data model. Important cloud service products are AWS DynamoDB or Azure Cosmos DB. They enable developers to store key-value-pairs as well as the more complex documents.
| Key | Value |
| 114.5.82.4 | 20.07.2020 09:32 |
| 14.1.219.55 | 20.07.2020 09:31 |
| 154.2.23.1 | 20.07.2020 09:30 |
| 124.5.8.4 | 20.07.2020 05:47 |
| 4.210.182.7 | 19.07.2020 22:09 |
Figure 2: Key-Value Store Example
Document Databases
Documents are semi-structured with the most popular file formats being XML and JSON. Documents allow for flexibility regarding the attributes (e.g., documents can have different structures) and they allow nesting attributes. The following two sample documents have a similar structure, but there are nuances. Document A contains an attribute “event” that document B does not have. Also, both documents store the author’s name a little bit differently.
| Document A |
| {
“article”: { “title”: “Business Applications: On the Tension between Efficient Testing and Compliance.”, “author”: “Klaus Haller” “journal”: “Softwaretechnik-Trends”, “year”: 2015, “volume”: 35, “event”: “37. Treffen der GI-Fachgruppe Test, Analyse & Verifikation von Software (TAV), Friedrichshafen, 5./6.2.2015” } } |
| Document B |
| {
“article”: { “title”: “Mobile Testing”, “journal”: “ACM SIGSOFT Software Engineering Notes” “author”: { “firstname”: “Klaus”, “lastname”: “Haller” } } } |
Graph Databases
Graph databases make modeling and querying complex topics and relationships intuitive. Social networks are a great application area. A graph consists of nodes and of edges that connect nodes. Nodes can, for example, represent persons or topics. Both, nodes and edges, can have attributes to store additional information. In the example in Figure 3, there are various types of nodes: individual persons, a band named Spice Girls, their albums, and some of their songs. The edges represent the relationships like being part of the band, they released an album, or a song is part of an album. There are also sample attributes like when the band membership ended or their nicknames. Not all attributes are used for every node or graph. For example, the graph database product Neo4J refrains from strictly enforced schemas.
One important aspect of graph databases is that everything you can model in a graph database you can model in a SQL database as well. Certainly, graph databases might outperform SQL databases for usage scenarios and/or can incur much lower costs.
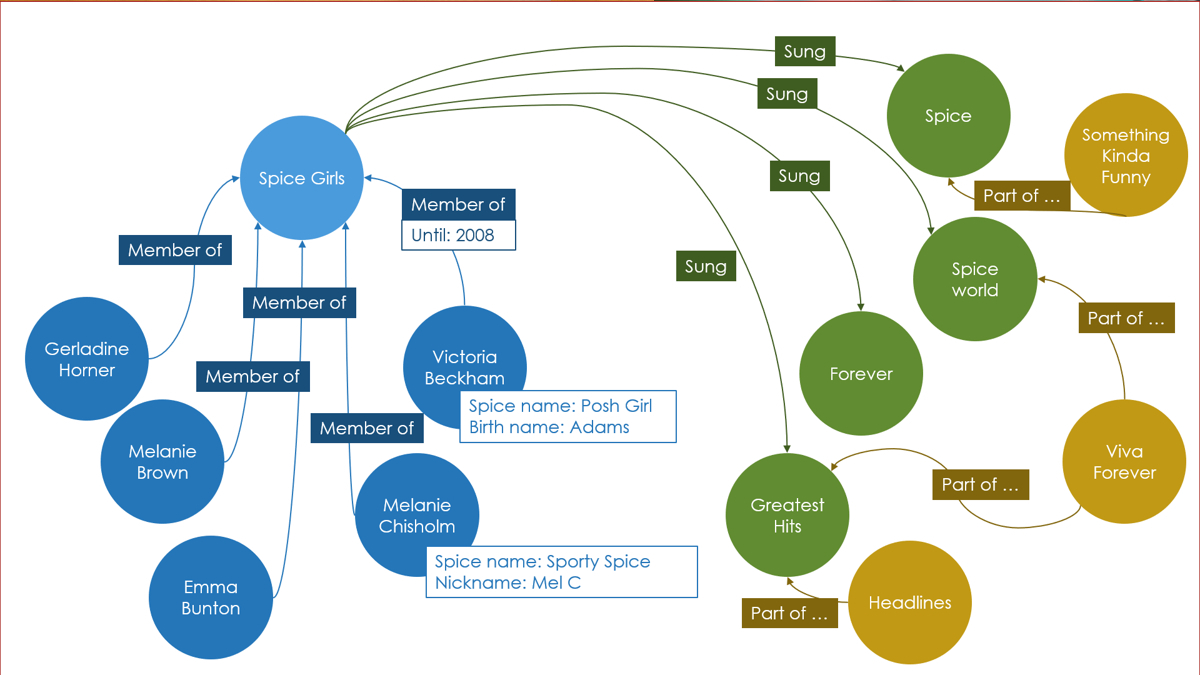
Figure 3: Representing the Spice Girls in a Graph Database
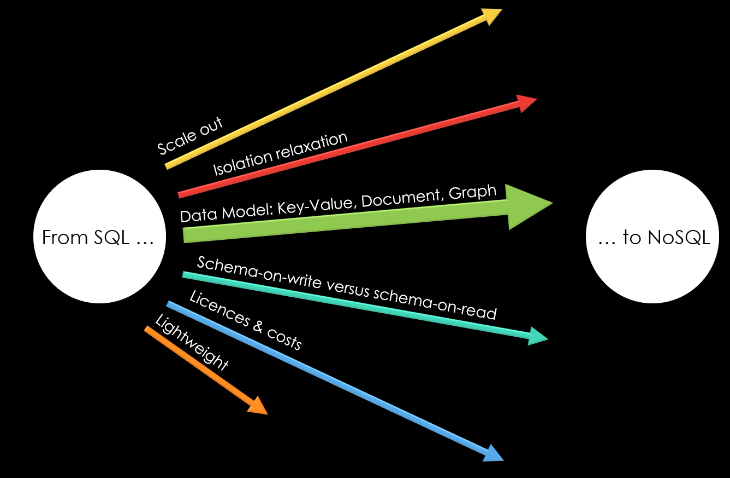
NoSQL beyond Data Models
Supporting different or restricted data models is one aspect of NoSQL databases, but there are more (see Figure 4). Many are lightweight and/or base on a schema-on-read instead of the well-known schema-on-write approach. In the case of schema-on-read, databases do not validate data or documents submitted for storage. For example, they do not reject data tuples with an unknown attribute. A schema-on-read database used for invoices, can – without any modification – store social media posts and sensor data as well. When querying a schema-on-read database for calculating the average invoice amount, the database considers only documents and data that matches the data structure of the query. The database ignores all other data.
Another common feature for NoSQL databases, especially for NoSQL database services of global cloud providers is scaling out horizontally on a global level. A typical example is AWS’s DynamoDB. When implementing such a service, there are two challenges:
- Applications and databases must be geographically close. This is a technical prerequisite for quick query responses. When users and applications are in Europe, so must be the database service. Thus, applications with a worldwide user base require database replicas around the globe, which must be somehow synchronized.
- Massive scalability requires scaling out horizontally. Improving performance must be achieved by adding new commodity servers instead of upgrading powerful servers and clusters to even better hardware. The area of supercomputers in the sense of a Cray with highly optimized hardware for a few customers and installations is over.
This conflicts with requirements to deliver always the most up-to-date data or to isolate transactions as known from SQL databases. Thus, NoSQL databases or database services might provide different guarantees than traditional databases. This does not impact, for example, social network applications such as LinkedIn or Facebook. They (mostly) read and present a lot of data. Data inconsistencies are unlikely, and the data can be a few minutes late. However, laxer guarantees can pose challenges for complex financial transactions and systems.
Licenses and costs can be another reason to choose a NoSQL database. This might not be obvious. There are mature and free SQL databases such as MariaDB. So, why would one choose a NoSQL database for cost reasons? In many cases, MariaDB is a viable option. However, enterprise-level features and support, high-performance cluster functionality, or massive scalability needed for data lakes requires expensive enterprise editions of the traditional SQL database vendors. These license costs can be quite high. Thus, NoSQL databases can be a cost-effective solution when massive throughput is important.
Is it worth it?
Starting with many NoSQL databases is (too) easy for developers today. First, NoSQL databases provide query languages whose syntax is heavily inspired by SQL. Developers are productive from the beginning. Second, many are free to download and/or to start with. Thus, every developer himself can “introduce” new technologies in the company. This can have a long-term impact on the architecture and the IT department:
- NoSQL databases are less standardized. They have a different data model, trade performance for (some) ACID guarantees, etc. They are good for a niche, but the product lock-in is high.
- Every new technology induces costs because engineers have to know the technology and support it for years (see my article “5 IT Operations Cost Traps and How to Avoid Them”, https://www.infoq.com/articles/operations-traps-avoid).
In short, NoSQL databases can be beneficial but are not guaranteed to be. Many IT organizations already use them, even if they are not always wanted from an architectural perspective. Fighting against them does not make sense. It is more efficient to understand the exact requirements developers have who want to use them. This allows evaluating technology alternatives already in use within the company, i.e., to judge whether there is a real need for a new NoSQL database product. If you cannot achieve goals with the organization’s standard technologies, introducing a new NoSQL technology might be worth it – just be aware of the long-term consequences for architecture, development, and maintenance.
See Also: