In this article, you’ll install InfluxDB on Ubuntu 20.10, InfluxDB is an open-source time-series DB that is capable to handle high write and query loads. In this article, we’ll see the installation and configuration of InfluxDB.
Steps to install InfluxDB on Ubuntu
InfluxDB is an open-source database that is designed to handle time-series data. It is an excellent choice for storing and querying metrics, IoT data, and real-time analytics data. InfluxDB is widely used for monitoring, alerting, and visualization purposes.
In this tutorial, we will walk through the steps required to install InfluxDB on Ubuntu 20.10. We assume that you have a basic understanding of Ubuntu and command-line tools.
Step 1: Install InfluxDB repositories
sudo curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add - sudo echo "deb https://repos.influxdata.com/ubuntu bionic stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
Sample Output:
root@InfluxDB:~# sudo curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add - Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)). OK root@InfluxDB:~# sudo echo "deb https://repos.influxdata.com/ubuntu bionic stable" | sudo tee /etc/apt/sources.list.d/influxdb.list deb https://repos.influxdata.com/ubuntu bionic stable root@InfluxDB:~#
Step 2: Update the repositories
sudo apt update
Step 3: Install InfluxDB on Ubuntu
sudo apt install influxdb
Step 4: Start the InfluxDB Service
sudo systemctl start influxdb
Step 5: Enable InfluxDB to auto start on boot
sudo systemctl enable --now influxdb
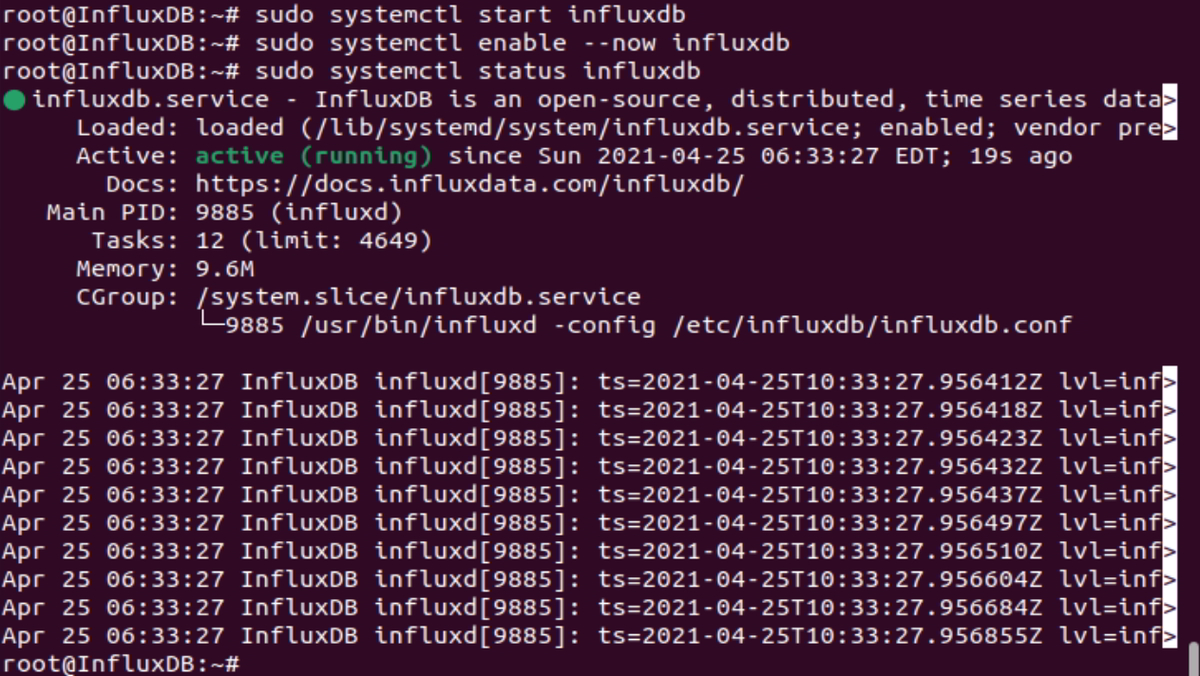
Step 6: Check the InfluxDB status
sudo systemctl status influxdb
Step 7: Configuring InfluxDB
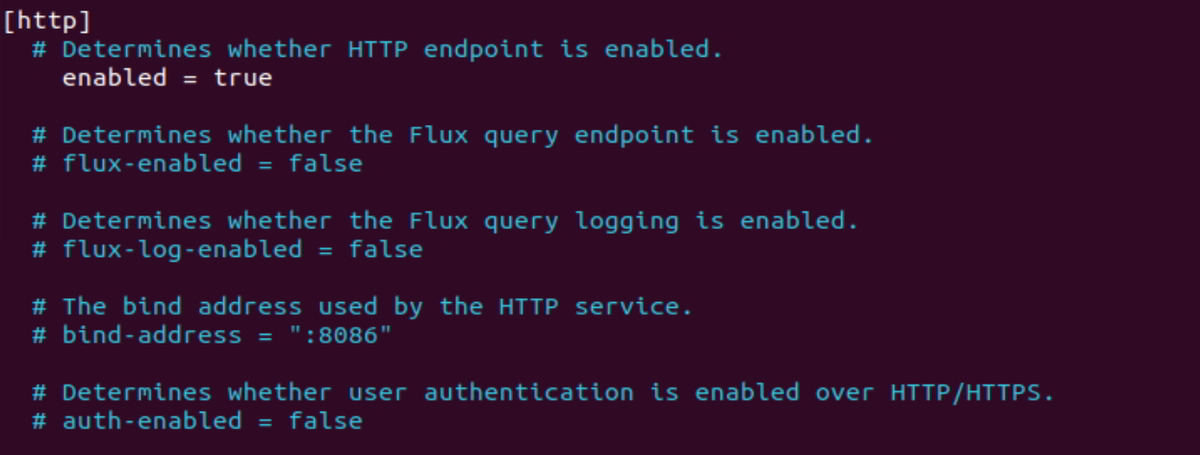
Locate InfluxDB configuration file /etc/influxdb/influxdb.conf
Most of the features by default disabled, to enable it you need to uncomment them.
To enable http request, uncomment the enabled line as shown in the below screen:
After changes save the file.
Whenever you do some changes to the influxdb.conf file you need to restart the influxdb service.
sudo systemctl stop influxdb && sudo systemctl start influxdb
Step 8: Create InfluxDB Administrator account
curl -XPOST "http://localhost:8086/query" --data-urlencode "q=CREATE USER influxdbadmin WITH PASSWORD 'Strongpassword' WITH ALL PRIVILEGES"
Sample Output:
root@InfluxDB:~# curl -XPOST "http://localhost:8086/query" --data-urlencode "q=CREATE USER influxdbadmin WITH PASSWORD 'Strongpassword' WITH ALL PRIVILEGES" {"results":[{"statement_id":0}]} root@InfluxDB:~#
In the above command replace username and password as per your need.
Step 9: How to access InfluxDB DB:
Syntax:
influx -username 'admin' -password 'password'
Create Database:
Once login you can create db:
CREATE DATABASE sysadminxpert_DB
Sample output:
root@InfluxDB:~# influx -username 'influxdbadmin' -password 'Strongpassword' Connected to http://localhost:8086 version 1.8.5 InfluxDB shell version: 1.8.5 > > CREATE DATABASE sysadminxpert_DB > > exit root@InfluxDB:~#
Run queries on InfluxDB
Syntax
curl -G http://localhost:8086/query -u ADMIN_NAME:PASSWORD_NAME --data-urlencode "q=QUERY"
Replace username, password and query which you want to run on InfluxDB.
View database from InfluxDB
curl -G http://localhost:8086/query -u admin:password --data-urlencode "q=SHOW DATABASES"
Sample Output:
root@InfluxDB:~# curl -G http://localhost:8086/query -u influxdbadmin:Strongpassword --data-urlencode "q=SHOW DATABASES" {"results":[{"statement_id":0,"series":[{"name":"databases","columns":["name"],"values":[["_internal"],["sysadminxpert_DB"]]}]}]} root@InfluxDB:~#
Create the Database User:
curl -XPOST "http://localhost:8086/query" \ --data-urlencode "q=CREATE USER influxdb1 WITH PASSWORD 'userstrongpassword' WITH ALL PRIVILEGES"
Sample output:
root@InfluxDB:~# curl -XPOST "http://localhost:8086/query" \ > --data-urlencode "q=CREATE USER influxdb1 WITH PASSWORD 'userstrongpassword' WITH ALL PRIVILEGES" {"results":[{"statement_id":0}]} root@InfluxDB:~#
Enabling the Firewall
– To access InfluxDB outside the machine then you need to allow it in firewall settings
sudo ufw allow 8086/tcp
Sample Output:
root@InfluxDB:~# sudo ufw allow 8086/tcp Rules updated Rules updated (v6) root@InfluxDB:~#
InfluxDB also supports a variety of other queries and commands, such as aggregations, group-by, and time-based queries. For more information on using InfluxDB, refer to the official documentation.
InfluxDB commands with an example:
1. Show databases:
The SHOW DATABASES command is used to display a list of all databases in InfluxDB.
> SHOW DATABASES name: databases name ---- _internal mydatabase
In the example above, the output shows two databases: _internal and mydatabase.
2. Create a database:
The CREATE DATABASE command is used to create a new database in InfluxDB.
> CREATE DATABASE mydatabase
In the example above, the mydatabase database is created.
3. Drop a database:
The DROP DATABASE command is used to delete a database from InfluxDB.
> DROP DATABASE mydatabase
In the example above, the mydatabase database is deleted.
4. Use a database:
The USE command is used to switch to a specific database.
> USE mydatabase
In the example above, the mydatabase database is selected.
5. Show measurements:
The SHOW MEASUREMENTS command is used to display a list of all measurements in the currently selected database.
> SHOW MEASUREMENTS name: measurements name ---- cpu disk
In the example above, the CPU and disk measurements are listed.
6. Create a measurement:
The INSERT command is used to create a new measurement in InfluxDB.
> INSERT cpu,host=serverA value=0.64
In the example above, a new measurement named CPU is created with a tag host and a field value.
7. Query data:
The SELECT command is used to query data from InfluxDB.
> SELECT * FROM cpu
In the example above, all data in the CPU measurement is displayed.
8. Aggregations:
InfluxDB provides various aggregation functions to aggregate data over time. For example, the MEAN function can be used to calculate the average value of a field over a specific time period.
> SELECT MEAN(value) FROM cpu WHERE time > now() - 1h GROUP BY time(10m)
In the example above, the MEAN function is used to calculate the average value of the value field in the CPU measurement over a 1-hour period, grouped by 10 minutes.
9. Limiting results:
The LIMIT clause is used to limit the number of results returned by a query.
> SELECT * FROM cpu LIMIT 10
In the example above, only the first 10 results of the CPU measurement are displayed.
10. Ordering results:
The ORDER BY clause is used to order the results of a query by a specific field.
> SELECT * FROM cpu ORDER BY time DESC
In the example above, the results of the CPU measurement are ordered by time in descending order.
These are some of the commonly used InfluxDB commands. InfluxDB provides many other commands and features for managing time-series data. For more information, refer to the official InfluxDB documentation.
InfluxDB FAQs:
Here are some frequently asked questions about InfluxDB:
1. What is InfluxDB?
InfluxDB is an open-source time-series database designed to handle high write and query loads. It is optimized for storing, querying, and visualizing time-series data, making it ideal for applications that require real-time monitoring and analysis of sensor data, metrics, and events.
2. What programming languages are supported by InfluxDB?
InfluxDB has client libraries for a variety of programming languages, including Go, Java, JavaScript, Python, Ruby, and more. This allows developers to easily integrate InfluxDB into their applications regardless of the programming language they are using.
3. Can InfluxDB handle high write loads?
Yes, InfluxDB is designed to handle high write loads with ease. It uses a distributed architecture that allows it to scale horizontally as write loads increase. In addition, it uses a highly optimized storage engine that is designed specifically for time-series data, making it very efficient at storing and retrieving data.
4. What types of data can be stored in InfluxDB?
InfluxDB is designed to store time-series data, which is any data that changes over time and is indexed by a timestamp. This includes sensor data, machine data, log data, performance metrics, and more.
5. Is InfluxDB suitable for real-time analytics?
Yes, InfluxDB is suitable for real-time analytics. It provides a powerful query language that allows users to perform complex analytics on time-series data in real-time. In addition, it supports continuous queries, which allows users to automatically aggregate and downsample data as it is ingested into the database.
6. What is the difference between InfluxDB and other databases?
InfluxDB is specifically designed for storing and querying time-series data, which makes it more efficient and performant than general-purpose databases when it comes to working with time-series data. In addition, InfluxDB provides a powerful query language, built-in support for real-time analytics, and easy integration with popular visualization tools.
7. Can InfluxDB be used for Internet of Things (IoT) applications?
Yes, InfluxDB is well-suited for IoT applications. It is designed to handle high write loads, which is critical for collecting data from large numbers of sensors and devices. In addition, it provides real-time analytics and visualization capabilities, making it easy to monitor and analyze IoT data in real-time.
8. Is InfluxDB easy to install and use?
Yes, InfluxDB is relatively easy to install and use. It provides pre-built binaries for popular operating systems, as well as Docker images for easy deployment in containers. In addition, it has a user-friendly web-based administration interface and a powerful query language that makes it easy to work with time-series data.
9. Is InfluxDB suitable for large-scale deployments?
Yes, InfluxDB is suitable for large-scale deployments. It can be deployed in a clustered environment to handle high write and query loads, and it supports distributed queries to allow for efficient querying across multiple nodes. In addition, it provides built-in backup and restore capabilities to ensure data integrity in case of hardware failures.
10. Can InfluxDB be used with other tools and technologies?
Yes, InfluxDB can be integrated with a wide range of tools and technologies. It has native integrations with popular visualization tools like Grafana and Chronograf, as well as with data collection tools like Telegraf. In addition, it provides a HTTP API that allows users to easily integrate it with custom applications and workflows.
11. Is InfluxDB a NoSQL database?
Yes, InfluxDB is a NoSQL database. It uses a schemaless data model and provides flexible indexing and querying capabilities, making it ideal for storing and querying time-series data.
12. Can InfluxDB be used with cloud platforms like AWS and Azure?
Yes, InfluxDB can be used with cloud platforms like AWS and Azure. It provides pre-built images for popular cloud platforms, as well as support for containerization using Docker. In addition, it can be deployed in a clustered environment on cloud platforms to provide high availability and scalability.
13. Is InfluxDB suitable for financial and banking applications?
InfluxDB may not be the best choice for financial and banking applications due to regulatory compliance requirements and the need for transactional consistency. However, it can be used for applications that require real-time monitoring and analysis of financial data, such as stock market analysis and trading systems.
14. Does InfluxDB provide security features?
Yes, InfluxDB provides a range of security features, including authentication and authorization, HTTPS encryption, and support for LDAP and OAuth. In addition, it provides data encryption at rest and in transit, as well as support for fine-grained access control.
15. Is InfluxDB suitable for high-availability applications?
Yes, InfluxDB is suitable for high-availability applications. It provides built-in support for clustering, replication, and failover, allowing it to provide high availability even in the event of hardware failures. In addition, it supports backup and restore to ensure data integrity in case of data loss or corruption.
Conclusion
InfluxDB is a powerful and flexible database that is designed to handle time-series data. In this tutorial, we walked through the steps required to install InfluxDB on Ubuntu 20.10. We also covered some basic InfluxDB commands for creating databases, measurements, and querying data. With this knowledge, you should be able to get started with InfluxDB and use it to store and query time-series data.
End of article – We’ve explained how to install InfluxDB on Ubuntu 20.10